1) 음성인식 이란?
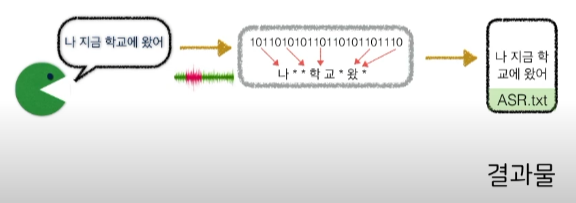
- 기계로 하여금 인간의 말소리를 인식하고 그 결과를 문자로 출력해주는 시스템
- ex) Apple의 Siri, 삼성의 빅스비
2) 음성인식 구현
- 영어를 아예 모르는 상태라고 가정하자
- 이 때, 영어 문장을 자주 들음으로써 어떤 문장이 영어인지 아닌지 판단할 수 있게 된다.
- 이렇게 영어 음성에 대해 익숙해지는 과정을 음성인식에서는 '음향모델' 혹은 'acoustic model'을 훈련한다고 한다.
- 음성인식을 위해서는 음향모델과 언어모델의 학습이 필요하다.
3) 음향모델(acoustic model)
- 음향모델을 훈련하는 것은 특정 언어에 존재하는 모든 음소를 배우는 과정
- 음소란?
- (영어) a, b, c, d ... 와 같이 가장 작게 쪼개진 소리 단위
- (한국어) 하나의 소리도 인식되는 것, 단어의 뜻을 구별해주는 말소리의 최소 단위 ex) 강, 방 -> 'ㄱ'과 'ㅂ'이 음소에 해당
- 다양한 문장을 들음으로써 배우게 된다.
- 단순히 독립적인 음소만 듣고 배우는 것이 아니라 음소의 변이형까지 학습한다.
- 'a': apple에서는 '에'로 발음되고 acoutic에서는 '어'로 발음된다.
- 위의 과정을 통해 영어스러운 억양과 발음을 학습하게 된다.
4) 언어모델(language model)
- 자연스러운 단어 나열 규칙 학습
- 특정 단어 다음에 나타나는 단어가 의미상, 문법상 어색하지 않은 상태
- '나는 학교를 00'에서 00에 들어갈 수 있는 단어: 간다, 갔어, 못 가
- 특정 언어에 존재하는 단어의 자연스러운 결합을 듣고 배우는 과정
- ex) '크림 줘'를 듣고 제빵과 관련된 언어모델은 '크림'으로 인식하고 화가와 관련된 언어모델을 '그림'으로 인식할 것이다.
- 즉, 사람마다 조금씩 다르게 생성될 수 있지만 기본적인 큰 틀은 비슷하다.
5) 기계가 학습하는 방법
- 기계는 '베이즈 정리'를 통해 음향모델과 언어모델을 학습한다.

- 기계에게 음성인식을 훈련시키려면 어떤 음성이 주어졌을 때, 그것은 어떤 문장이라는 조건부확률을 구해야 한다.

- 기계에게 주어진 음성은 오디오 파형이다.
- 하지만 위의 파형을 보고 어떤 문장인지 맞출 수 없다.

- 따라서 위와 같은 수식이 필요하다.

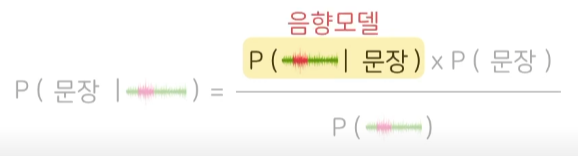
- 각 문장에 등장하는 음소들을 특정 조건으로 주고 그 음소들의 파형을 보여주면서 음향모델을 학습한다.
- 베이즈 정리에서 likelihood에 해당한다.



- 위와 같이 모든 음성에 대해 훈련시킨다.
- 그 결과 음향모델이 완성된다.


- 언어모델의 경우 뉴스, 소설과 같은 자료를 통해 각 단어가 등장하는 횟수 학습한다.
- 보통 2개, 3개 단어의 연쇄를 두고 그 단어의 연쇄의 등장 횟수를 학습한다.
- 베이즈 정리에서 prior에 해당한다.
- 해당 부분을 우리가 준비한 학습데이터를 이용해서 학습시키면 언어모델이 된다.


- 그 결과 음성인식모델이 완성된다.