1. 음성인식의 개념 및 특징
- 음성인식이란?
- 마이크나 센서를 통해 음향학적 신호를 단어나 문장으로 변환하고 해독하는 기술
- 사람의 입에서 나온 음성신호를 분석하여 자동으로 문자열로 변환해주는 기술
- ASR(Automatic Speech Recognition), STT(Speech-to-Text)라고도 부른다.
- input: speech acoustic singal (음성신호), output: best matched text (방대한 텍스트들의 조합)
- 음성인식의 전반적인 과정

- 음성신호가 들어옴 -> 스펙트로그램 생성 -> 스펙트로그램에서 추출된 특징 벡터로 추출 -> 특징 벡터가 음향 모델로 들어가서 음소 단위의 서브 워드로 분류 -> 발음 사전을 통해 단어가 됨 -> 언어 모델을 통해서 문장으로 분류
- 입력된 음성이 어떤 단어들로 이루어져 있을 확률이 가장 높은가?
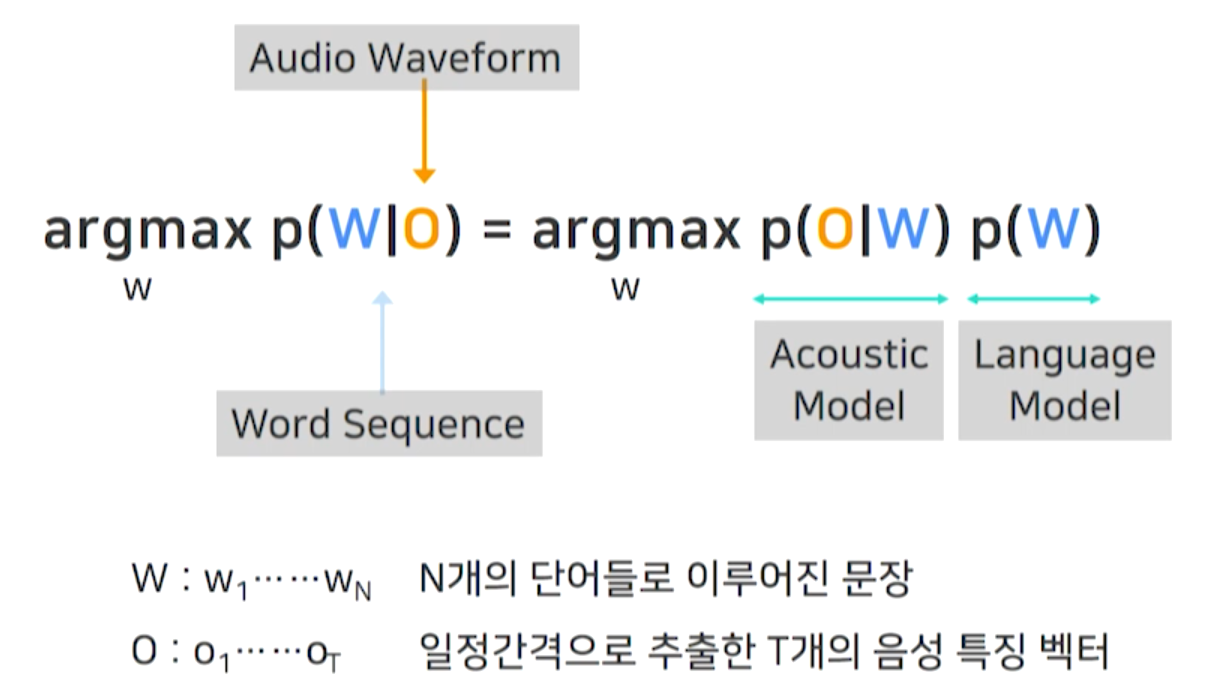
- 음성 특징 벡터가 주어졌을 때, 문장이 나올 확률을 가장 높게 하는 것
- 위의 내용을 직접적으로 풀 수 없기 때문에 베이즈 정리를 이용해서 구한다.
- 음성인식의 분류
- by 적용 화자: 화자 종속 / 화자 독립
- 화자 종속: 미리 등록한 특정 화자, 높은 인식 성능
- 화자 독립: 불특정 화자, 대용량 음성 DB
- by 발음 형태: 고립어 / 연속어
- 고립어: 단어 전후에 묵음 존재
- 연속어: 연결 단어, 연속 문장, 대화체, 다양한 발음 변이를 고려한 언어 모델, 핵심어 인식
- by 어휘 크기: 소용량 / 대용량
- 소용량: 수 백 - 수 천 단어, 단어 모델, 문맥 독립형 모델
- 대용량: 수 백만 단어 이상, 문맥을 고려한 sub-word (형태소) 형태의 모델 단위
2. 음성인식의 구조
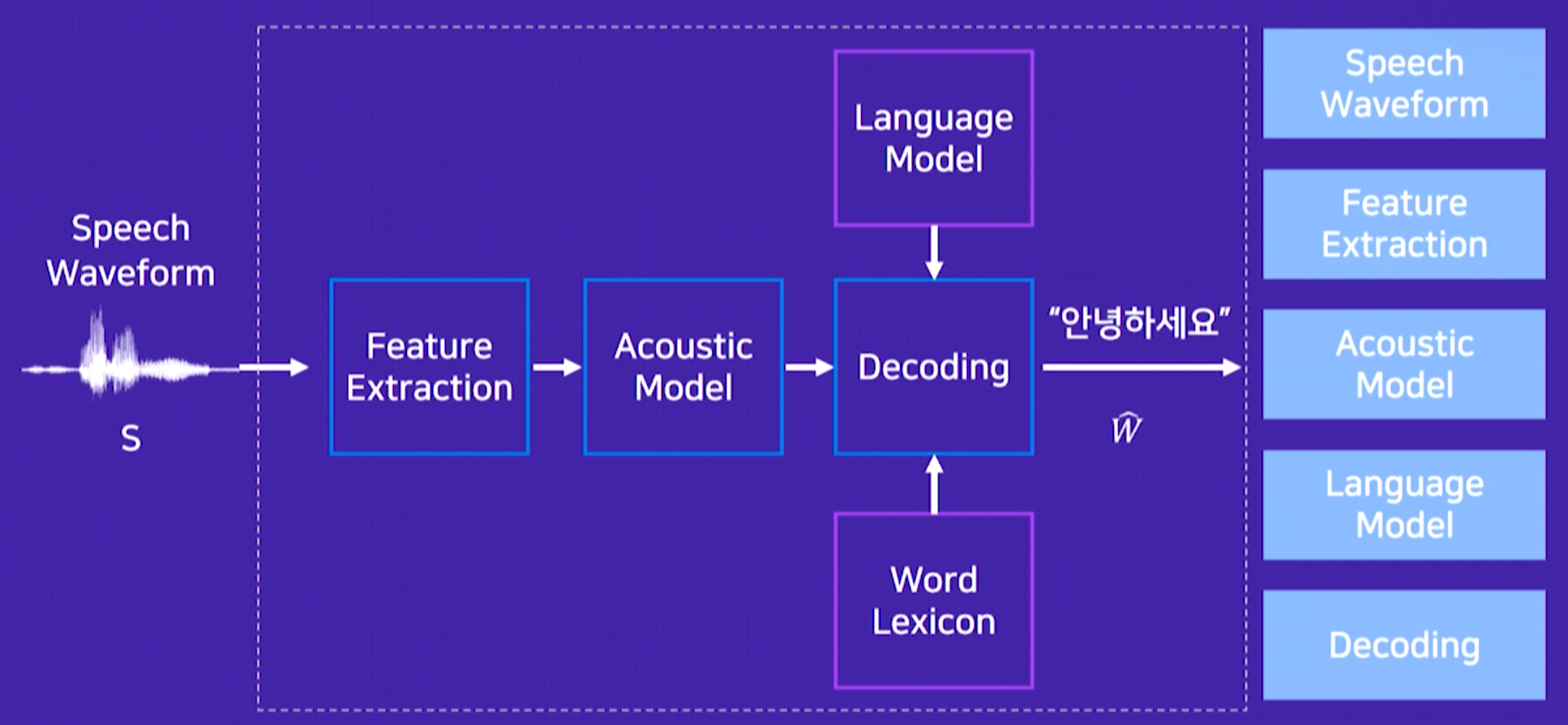
- Feature Extraction: 음성 특징을 추출
- Word Lexicon: 발음 사전
- 음성 분석: 음성신호에서 주파수 분석을 통해 음성의 특징이 되는 부분을 추출하는 과정

- Pre-Emphasis: 주파수를 증강하는 부분
- Sampling and Windowing: 아날로그 신호를 디지털로 바꾸고 난 후 프레임 단위로 쪼개는 과정
- Fast Fourier Transform: 시간 축에 있는 음성 데이터를 주파수 축으로 바꾸는 과정
- Mel Filter: 청각이 이해할 수 있도록 주파수 대역을 낮은 주파수는 넓게, 높은 주파수를 좁게 하는 필터로서 사람이 가장 잘 들을 수 있는 모델을 사용하는 필터 뱅크
- Discrete Cosine Transform(DCT) 연산: mel spectrogram을 discrete cosine transform을 통해 MFCC로 만들어내는 과정
- 음향 모델: 음성 특징 분석을 통해 만든 특징 벡터 열과 어휘 set에 대한 확률을 학습하는 과정

- GMM: 사람 음성의 음소를 모델링
- HMM: 음성의 변화 시퀀스를 모델링
- 전통적으로 GMM-HMM 모델이 음향 모델의 주축을 이뤘다.
- 2010년대 이후로부터는 딥러닝이 적용되면서 DNN-HMM의 하이브리드 모델, LSTM이 적용되면서 LSTM-HMM 모델이 주류를 이루고 있다.
- 최근에는 End to End 모델이 등장하면서 획기적으로 음향 모델의 성능이 올라가고 있다.
- 언어 모델: 방대한 텍스트를 분석해 모델을 만들어 현재 인식되고 있는 단어들 간의 결합 확률을 예측하는 과정
- 언어 모델은 특정 단어 열이 주어졌을 때 다음에 나올 단어의 확률을 추정하는 모델 (문장 생성 확률 계산)


- 디코딩: 음향 모델과 언어 모델로 구성된 탐색 공간에서 가장 최적인 경로를 찾는 과정, 음성이 어떤 단어 열을 나타내는지 추정

- 문자열과 관측치의 두 개의 확률을 최대로 하기 위해 arg max를 한다.
- arg max에 대한 부분이 디코딩하는 부분
- 이런 복잡성으로 인해 과거에는 Lexical Tree 알고리즘을 사용했다.
- 최근에는 WFST라는 알고리즘을 사용하면서 성능이 많이 좋아졌다.
- 출처
- http://www.kocw.net/home/cview.do?cid=d10faf9660b7b0e5
- 해당 글은 KOCW에서 제공하는 'AI 보안 음성인식' 강의를 듣고 정리한 내용입니다.