1) CTC가 필요한 이유
- 일반적인 Speech Recognition에서 데이터셋으로 오디오 파일과 transcript(텍스트)를 받게 된다.
- 이 때, 어떤 단어의 character가 audio와 alignment가 맞는지 알 수 없다.
- alingment 없이 어떤 audio와 text 사이의 규칙을 정의하기 어렵다.
- 또한, 사람들마다 발화 스타일이 다른데 (ex. apple: '애플', '애-플', '애--플' 등) 하나의 규칙으로 정의하기에는 무리가 있다.
2) CTC의 기본 idea
- 우리는 input과 output 사이의 정확한 alignment가 되어있는 데이터셋이 필요하지는 않는다.
- 주어진 input에 대해서 output의 확률 값이 필요하다.
- CTC는 둘 사이의 가능한 모든 alignment의 가능성을 합산하여 작용한다.
(The basic idea is to interpret the network outputs as a probability distribution over all possible label sequences, conditioned on a given input sequences. - CTC 논문 인용)
- 즉, input과 output 사이 가능한 align을 모두 뽑아서 marginalize 하겠다는 의미다.
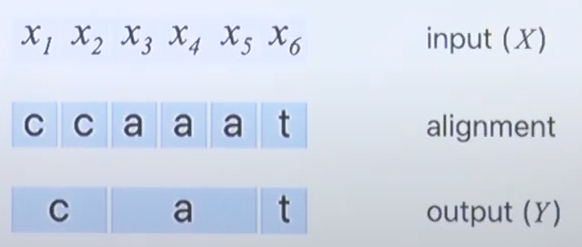
3) CTC의 내용
- 발화에는 띄어쓰기, 묵음 등이 존재할 수 있다.
- \epsilon이라는 토큰을 추가한다.
- CTC는 input과 같은 길이의 alignment를 만들고 y로 mapping 하면서 \epsilon을 제거하면 해당 output과 길이가 같은 결과를 얻을 수 있다.

- 'hello'만 하더라도 다양한 발화 방법이 존재한다.
- 따라서 가능한 모든 alignment를 고려한 모델을 만드는 것이 CTC의 방법이다.
- 하나의 input에서 next input으로 진행하면서 output을 동일하게 유지하거나 next output으로 assign한다. (즉, 순서가 중요하다.)
- X와 y의 정렬이 many-to-one 함수다. (하나 이상의 input이 output에 들어갈 수 있다.) (역은 성립하지 않는다.)
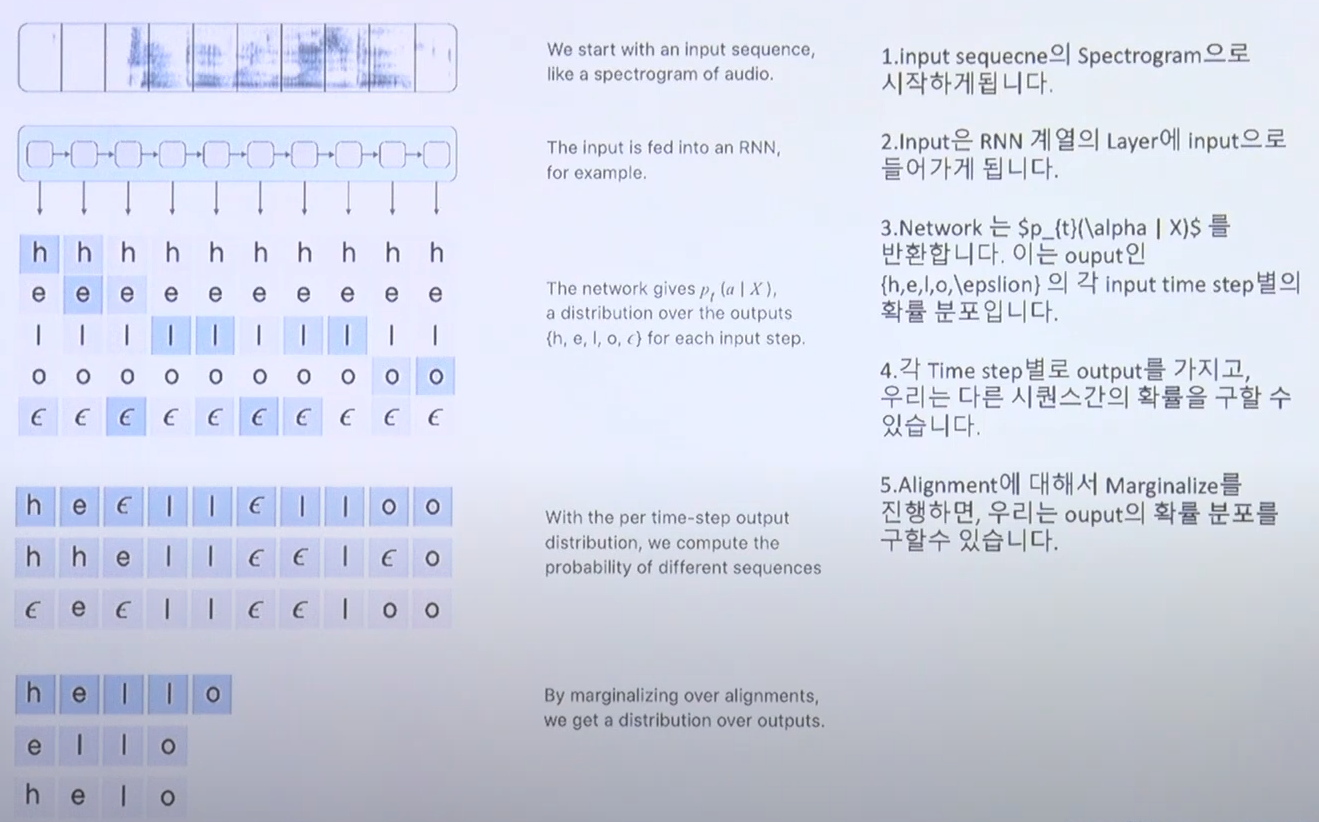
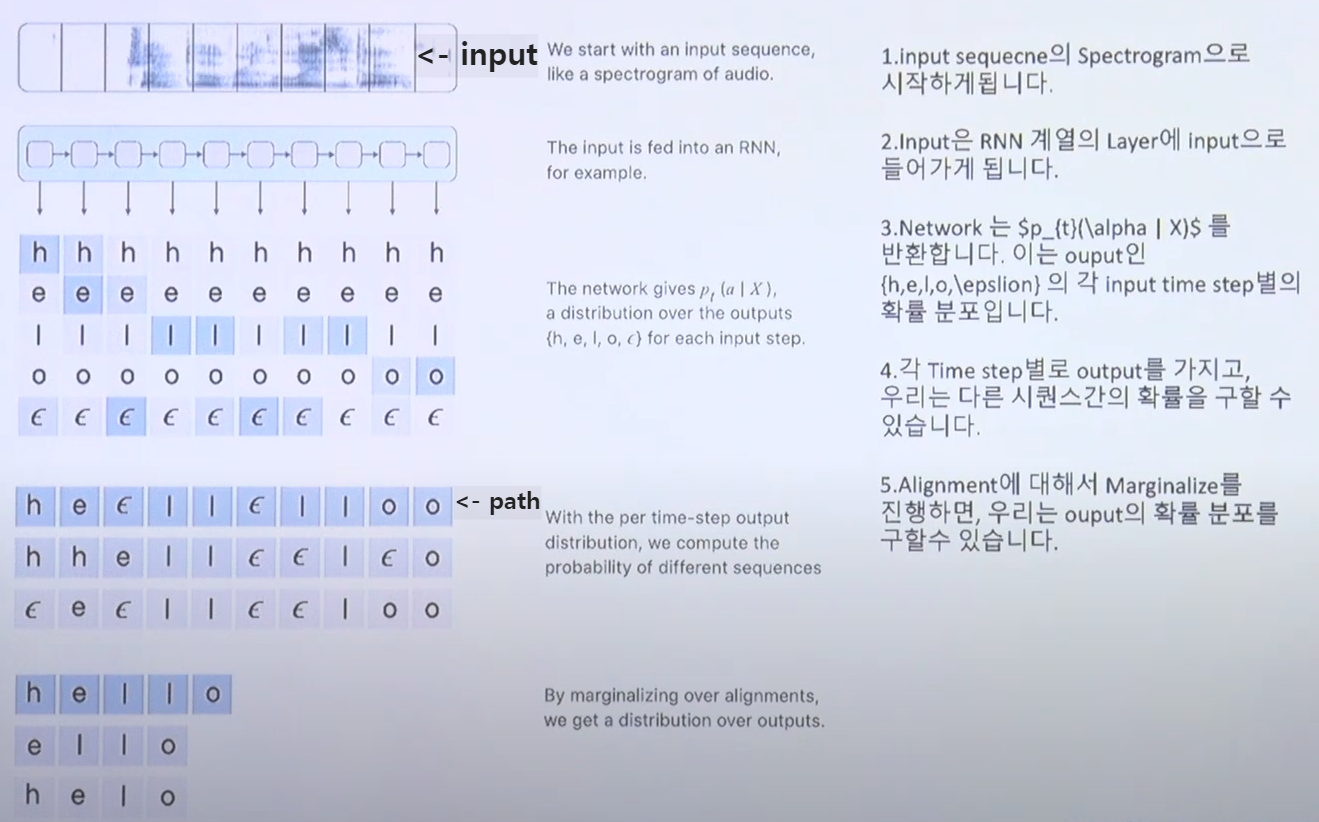
- final layer에서 softmax로 time에 대해서 가능한 모든 알파벳의 분포를 return한다.
- softmax의 결과가 CTC input으로 들어가게 된다.

- invalid한 alignment는 marginalize 과정에 사용되지 않는다.
- CTC는 RNN 기반의 모델이다.
- input spectrogram이 RNN을 통과하게 되고 그 결과(output)로 [알파벳 단위 + 띄어쓰기 + special token]의 전체 distribution이 나오게 된다.
- 각각 time step별로 전체 알파벳 집합의 확률분포가 return된다.
- alignment에 대해 marginalize를 진행하면서 output의 확률분포를 구하고 최종 distribution을 찾게 된다.
* spectrogram이란? (출처: https://ahnjg.tistory.com/93)
- 푸리에 변환(Fourier Transform)을 하면 음성에 각 진동수 성분이 얼마나 들어있는지를 알 수 있다.
- 즉, 음성 신호에 저음과 고음이 각각 얼마 들어있는지를 정량적으로 구할 수 있다.
- 음성을 작게 (0.01초 수준) 잘라서 각각의 작은 조각에 푸리에 변환을 적용할 수 있다.
- 이것을 STFT(Short Time Fourier Transform)이라 하고 이 결과의 L2 norm을 spectrogram이라고 한다.
4) CTC의 내용2

- CTC는 조건부확률이다.
- X(input)는 spectrogram, Y는 sentence의 transcription이다.
- (X,Y)의 pair dataset에 대해서, 각각의 X는 input step을 따라가면서 step-by-step으로(시간축을 따라감) single alignment의 확률을 계산한다.
- 그 후, validation alignment에 대해서만 (invalidation alignment는 제외) marginalize를 진행한다.
- CTC는 time step별 확률 분포를 얻기 위해서, 그리고 input sequence의 context를 고려하기 위해서 RNN 기반의 모델을 통해 학습한다.
- 하지만 RNN은 input sequence가 fixed-size slice일 때 활용하기 더 좋다.
5) CTC 모델이 학습하는 parameter
- RNN의 parameter는 hidden state에 곱해지는 weight, input에 곱해지는 weight, output에 곱해지는 weight다.

- L: 레이블 세트, L': \epsilon이 있는 레이블 세트
- 𝝿: 길이가 T인 sequence 안에서 가능한(valid) 경로(path)의 집합
- B: marginalize 하는 것
- 주어진 데이터에 대해 가능한 𝝿를 모두 계산하고 어떤 marginalize하는 mapping에 대해 모두 summation한다.
- 그러면 input(=audio spectrogram)이 주어졌을 때, 가장 probability가 높은 어떤 z(=path)를 찾는 것이 목표
- input이 들어왔을 때, path를 찾는 RNN의 parameter를 학습하는 것이 CTC
- CTC의 loss를 보통 speech recognition의 loss function으로 잡고 학습을 시킨다.
6) 목적 함수(Objective function)
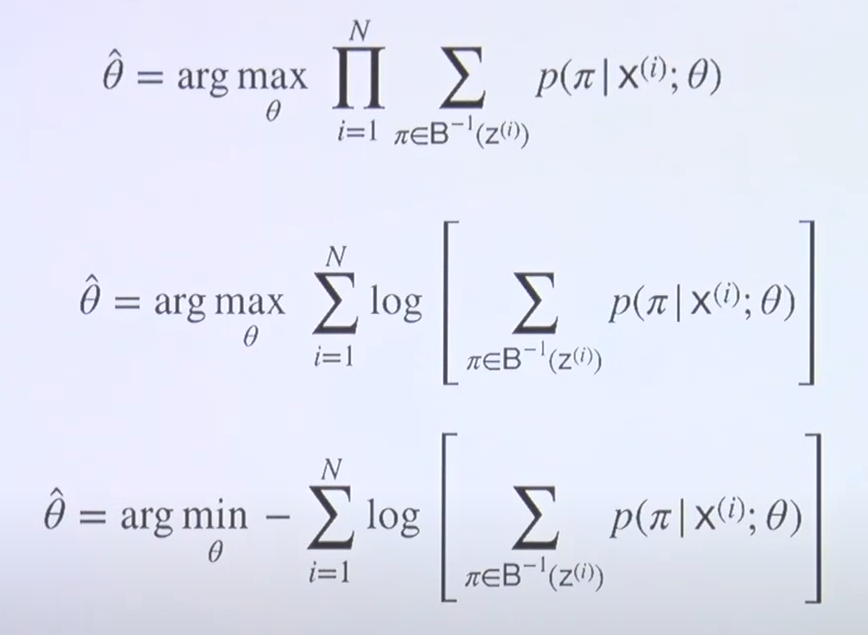
- maximum likelihood estimate를 log를 취해 형태를 바꾸고 maxmization을 minmization으로 바꾼다.
- 이런식으로 가능한 모든 path를 찾게 되면 input sequence가 길어질수록 가능한 경우의 수가 많아져 연산량이 커지게 된다.
7) Classifier
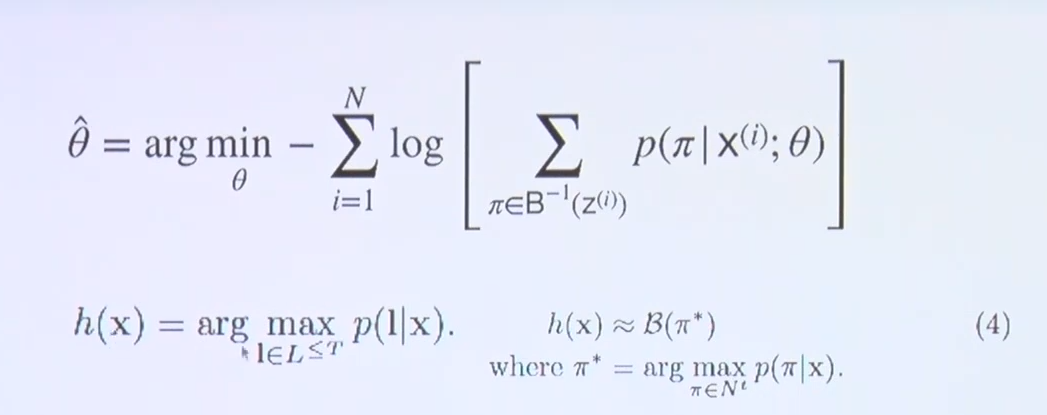
- 확률를 최대화 시키는 RNN 구조를 찾을 때, 가장 쉬운 방식은 given data에 의한 path의 확률에 argmax를 취하는 것이라고 논문의 앞부분에서 주장하고 있다.
- softmax로 output이 나오게 되는데, softmax에 바로 argmax를 취하면 그 softmax 중에 가장 확률 값 높은 것을 쓸 수 있다. (좋은 방식은 아니지만 구현이 간단하다. / 이것으로 실습을 진행할 예정)
- 그러나 논문에서 이 방법 대신에 dynamic programming으로 beam search 하자고 제안하고 있다. (해당 논문의 주된 contribution 중 하나)
8) Dynamic Programming
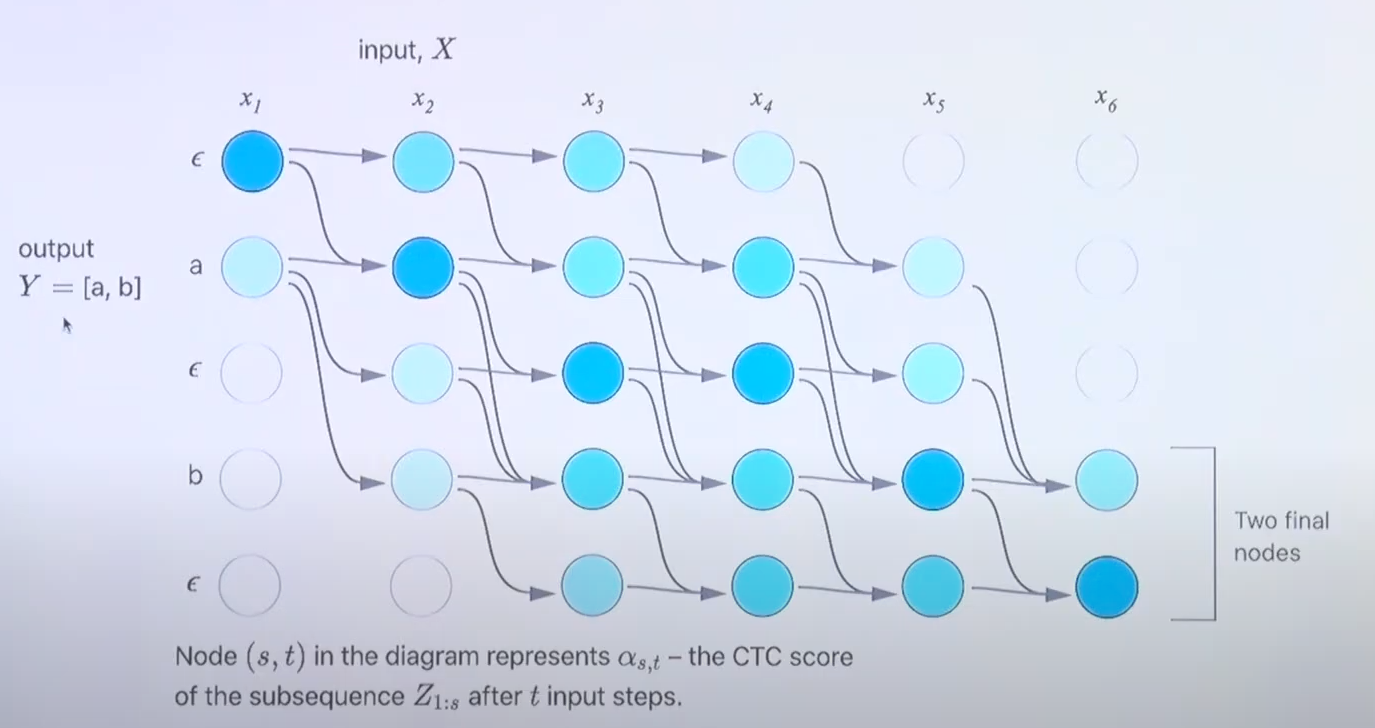
- output이 [a,b]라고 가정하자.
- 시작은 무조건 /epsilon 아니면 a이어야 한다.
- 위의 그림은 가능한 path를 표현한 그림이다.
- /epsilon이 계속 등장하더라도 적어도 5번째에서는 a가 등장해야 output이 [a,b]가 된다.
- 규칙에 의해 어느 정도의 path는 고정되어 있음을 알 수 있다.

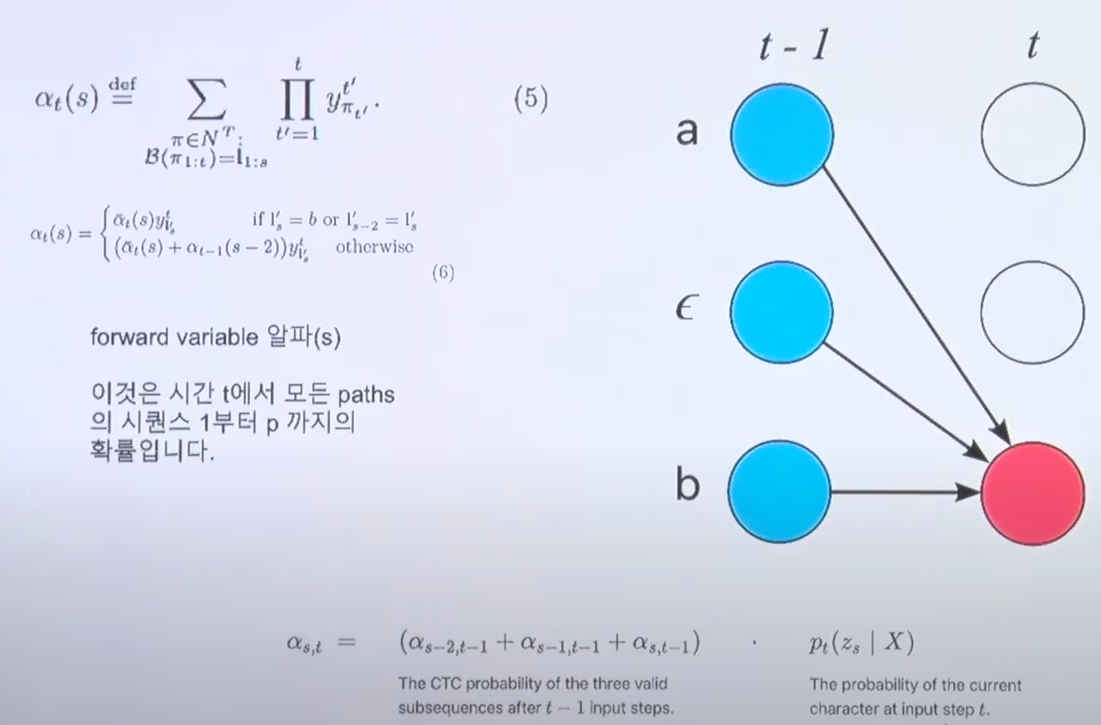
- 위의 개념을 수학적으로 표현한 것이 왼쪽의 dynamic programming의 forward variable이다.
- forward variable alpha는 t라는 시점에서 모든 path의 시퀀스(1부터 p까지)의 확률을 뜻한다.

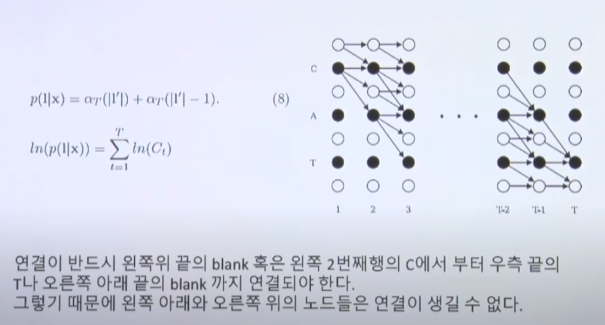
- 결론적으로 주어진 데이터에 대해서 가능한 가장 relevant한 path는 마지막 2개의 alpha값으로 설명할 수 있다.
9) 정리
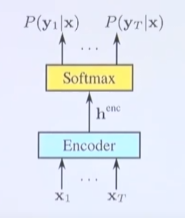
- CNN 쌓고, RNN 쌓아서 인코딩이 잘 된 것을 fully connected를 통과한 다음에 softmax를 취하면 각 time sequence 별로 probability distribution이 나오게 되고 이것을 CTC에 의해서 어떤 relevant한 path를 찾을 수 있게 된다.
- 이후 LAS 모델이 등장하였다.